2024年11月27日武汉科技大学计算机科学与技术学院副院长徐新教授在综二105学术报告厅开展了主题为“面向重识别任务的大规模图像数据交互式标注研究”的学术讲座。讲座由副院长裴浪教授主持,计算机学院师生共计300余人参与了本次讲座。

人工智能大模型的成功在很大程度上归功于"数据智能"和机器学习,即利用机器学习算法从数据中提取知识、模式和模型。大模型功能强大且易于展示,但如何将其广泛应用于各种场景一直是个难题。在许多垂直领域,利用完全监督或弱监督模型往往比直接使用大模型效果更好。为了有效解决垂直领域的实际问题,促进人工智能与实体经济的有效融合,大模型与业务数据的充分协同迫在眉睫。
徐新教授从什么是图像数据的交互式标注、基于主动学习的图像交互式标注、实验结果分析三个方面展开讲授。
一、什么是图像数据的交互式标注
交互式标注通过算法识别+人工判断的方式,允许用户与标注工具进行互动,以优化标注结果。这种方法特别适用于对标注精度要求较高且标注过程较为复杂的场景,如图像语义分割。徐教授介绍了以行人重识别任务为例的图像数据交互式标注,行人重识别(Person Re-ID)需要从海量的图像库中进行检索,具有数据量标注大、比较次数多、容易误辨识等问题。基于这类问题,使用少量的标注数据训练出一个有效的Re-ID模型是目前比较常用的解决方法,一般采用弱监督学习,即从少量标注数据中学习,但是标注数据直接影响着Re-ID模型的性能。徐教授及其团队提出了保证Re-ID模型整体性能的前提下,尽可能减少Re-ID数据集的手工标注量的方法。
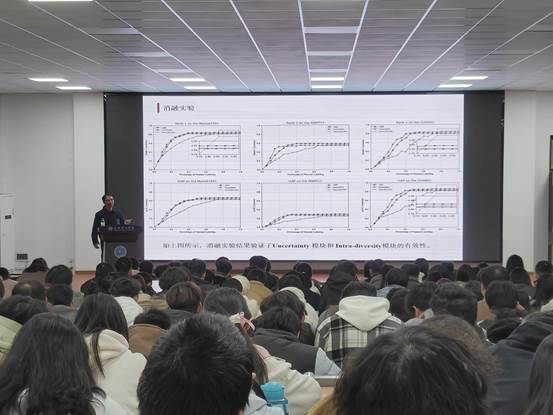
二、基于主动学习的图像交互式标注
主动学习(Active Learning,AL)是降低数据标注代价的重要方法。主动学习通过增量式标注数据,边标注边训练,直至模型性能达到要求。其一般过程是首先通过查询策略对未标注对象进行标注,为了有效标注样本,一般挑选代表性强、信息量丰富的样本。接着对通过查询策略标注后的图像集进行边标注边训练Re-ID模型。徐教授重点介绍了他们团队采取的两种查询策略。一种是Uncertainty (提供新的鉴别性模式样本) ,另外一种是Intra-diversity (提供全面的鉴别性模式样本)。徐教授及其团队采取了身份推荐模块(IDRM),在Market1501数据集上单个样本的对比次数上,随机方法需要比较751次,而身份推荐模块只需要比较20次以内。
三、实验结果分析
实验结果采用Market1501数据集,一个用于行人重识别(ReID)的大规模公共基准数据集。其数据集图片采集自清华大学校园的6个摄像头。结果显示提出的方法仅使用37%的数据标注量就基本达到了baseline的性能。同时消融实验结果验证了不确定性(Uncertainty) 模块和 内部多样性(Intra-diversity)模块的有效性。结果表明身份推荐模块 (IDRM) 可以降低大约100倍的比较次数。
讲座结束后,徐新教授和计算机学院师生就数据标注方法展开了热烈的互动和交流。同时,徐新教授最后也介绍了武科大和武汉晴川学院的联合培养研究生的模式,鼓励计算机学院学子积极报考武汉科技大学。


